파이썬 웹 크롤링 예제 알아 보겠습니다.
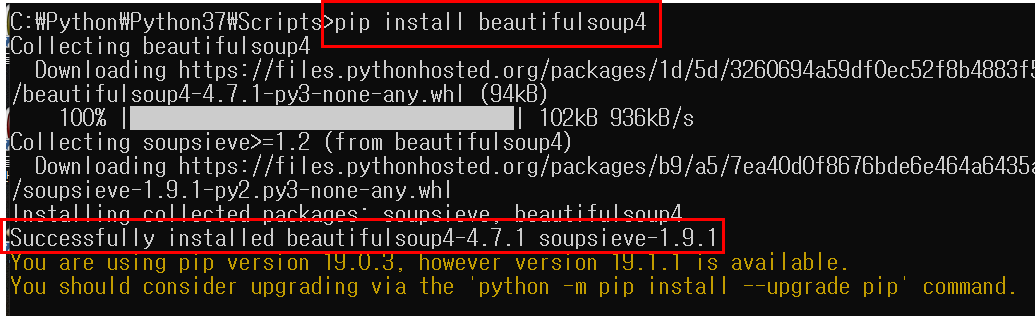
beautifulsoup 예제 입니다.
파이썬 설치를 하지 않으신 분은 파이썬 설치 링크 를 참고 하세요.
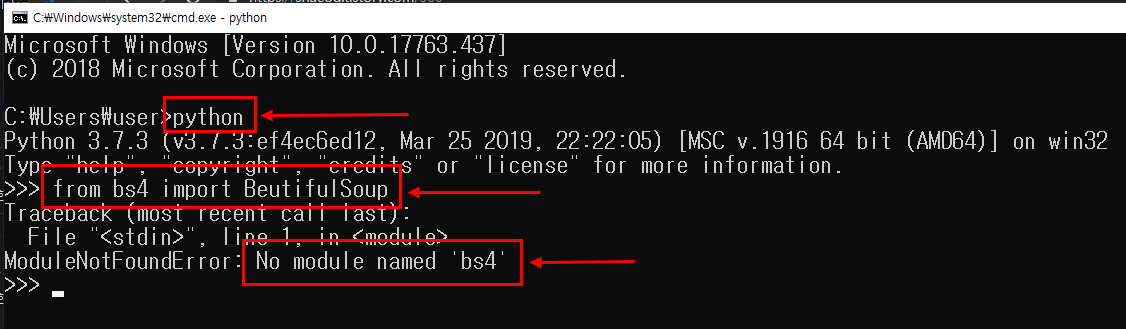
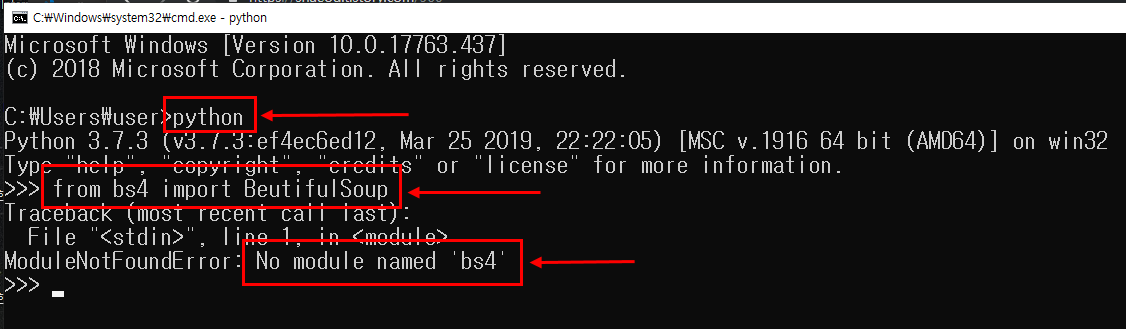
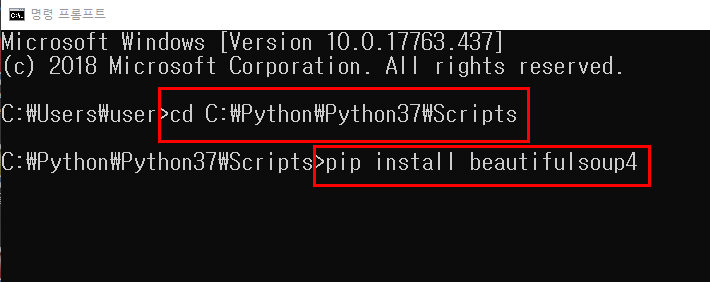
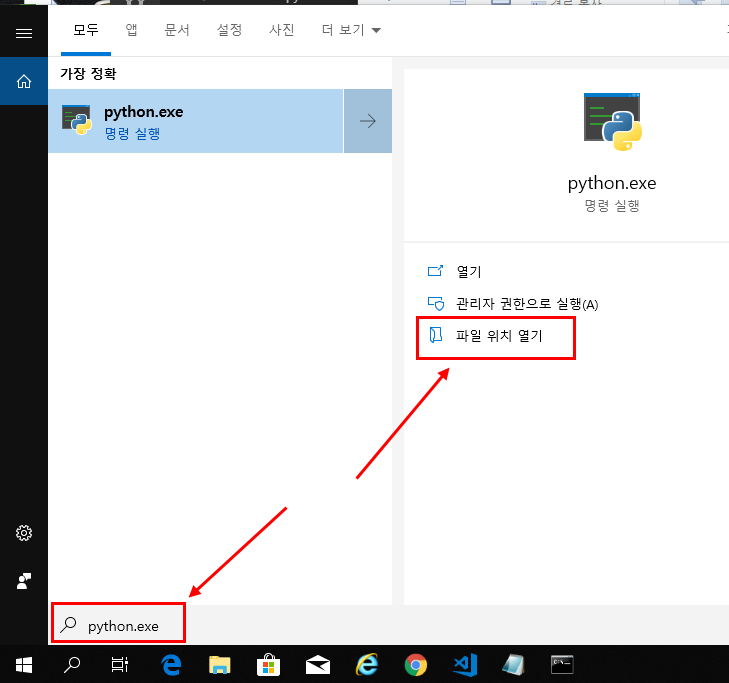
beautifulsoup을 설치 하지 않으신 분은 beautifulsoup 설치 링크를 참고 하세요.

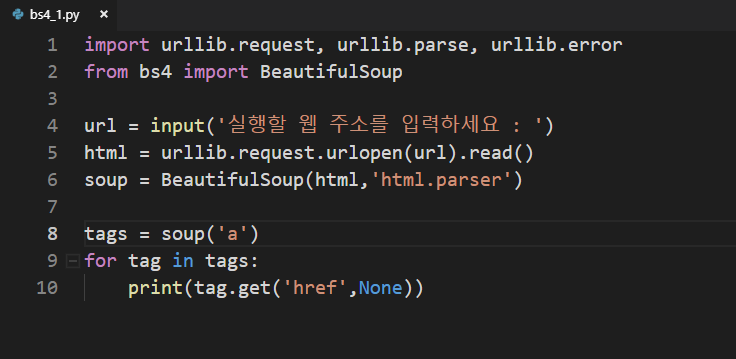
첫번째 네모 부분에는 어디를 크롤링 할지 물어보는 안내하는 문구 입니다.
input('~~~') : ~~~ 부분은 마음대로 변경하셔도 됩니다.
두번째 네모 부분은 어떤 태그를 크롤링 할지 정하는 문법입니다.
soup('~~~') : ~~~ 부분에 크롤링 원하는 태그로 변경하셔도 됩니다.
세번째 네모 부분은 두번째 네모에서 크롤링 한 태그 중에 어떤 단어가 있으면 그 단어에 해당하는 내용을 가지고 오라는 뜻입니다. 설명이 어려운에 실습하실 때 보시면 이해가 되실 겁니다.
prtin(tag.get('~~~',None)) : ~~~ 부분에 원하는 단어를 입력하시면 됩니다.

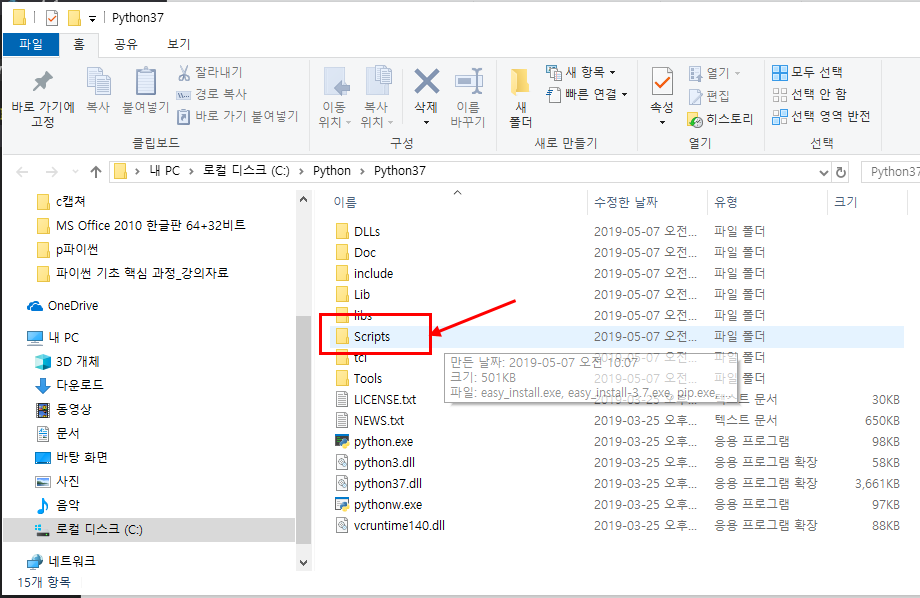
저는 위의 내용대로 개발을 한 후에 bs4_1.py 라는 파일명으로 저장하였습니다. 원하시는 파일명으로 저장하시면 됩니다.
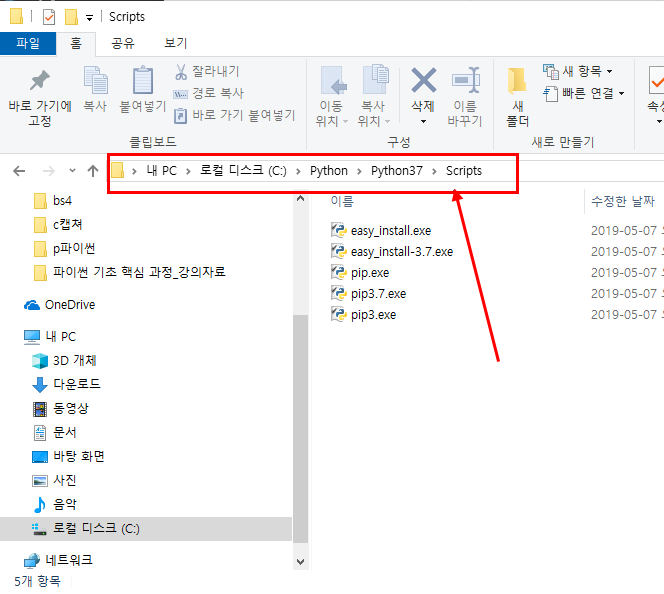
그리고 해당 파일이 저장되어 있는 위치로 가셔서 실행하시면 됩니다.
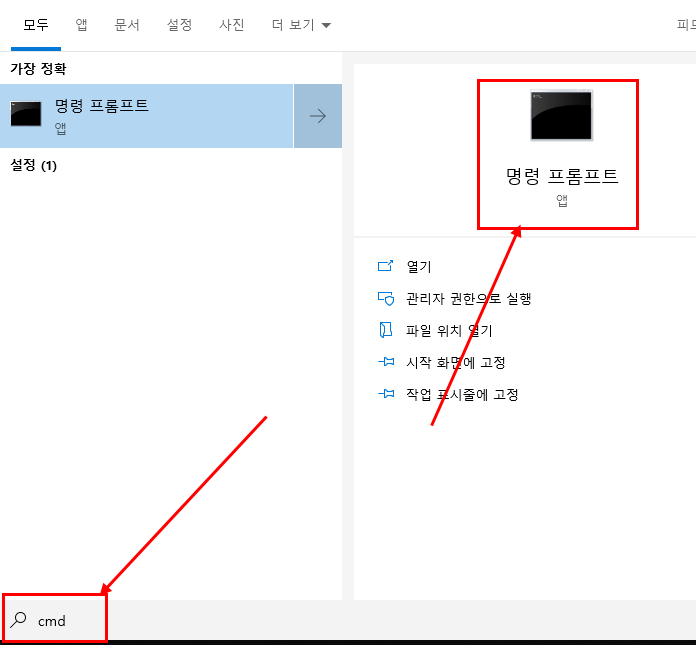
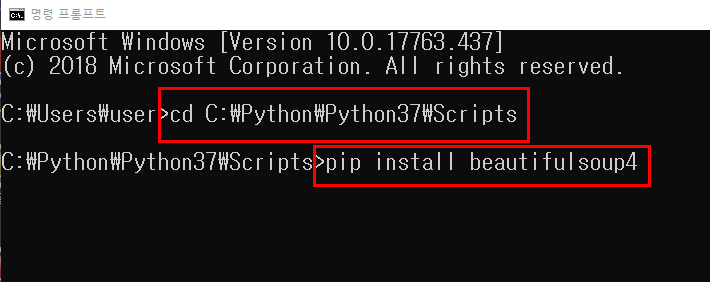
위의 그림처럼 명령 프롬프트를 실행하시면 됩니다. 윈도우에서는 윈도우버튼 + R 을 입력하시고 cmd 로 실행하셔도 됩니다.
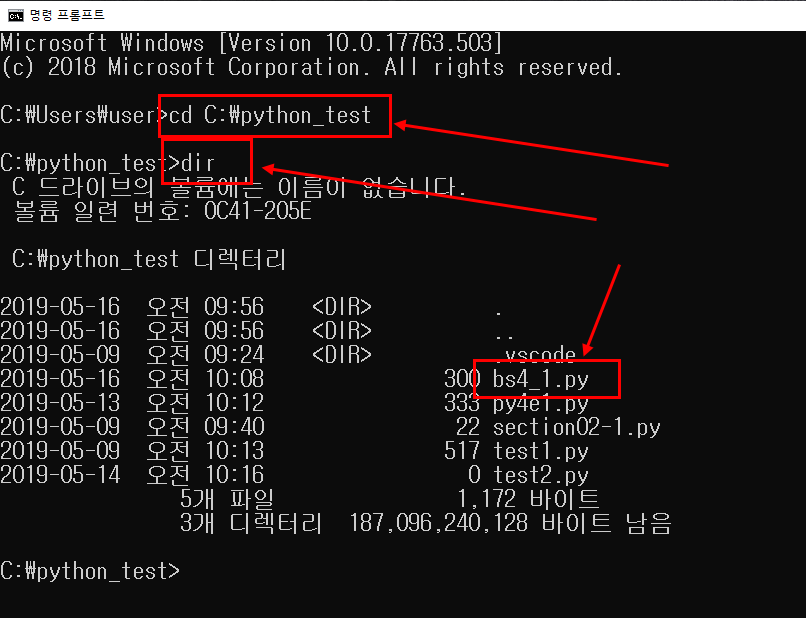
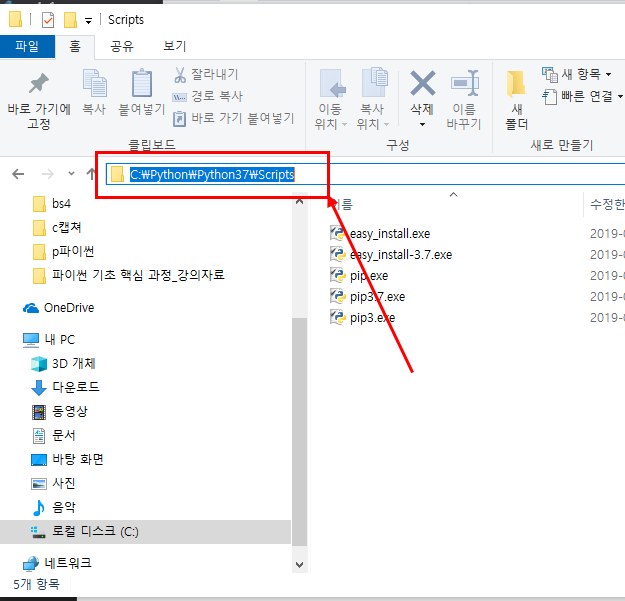
개발한 파일명 위치로 이동하셔서 해당 파일이 있는지 확인합니다.
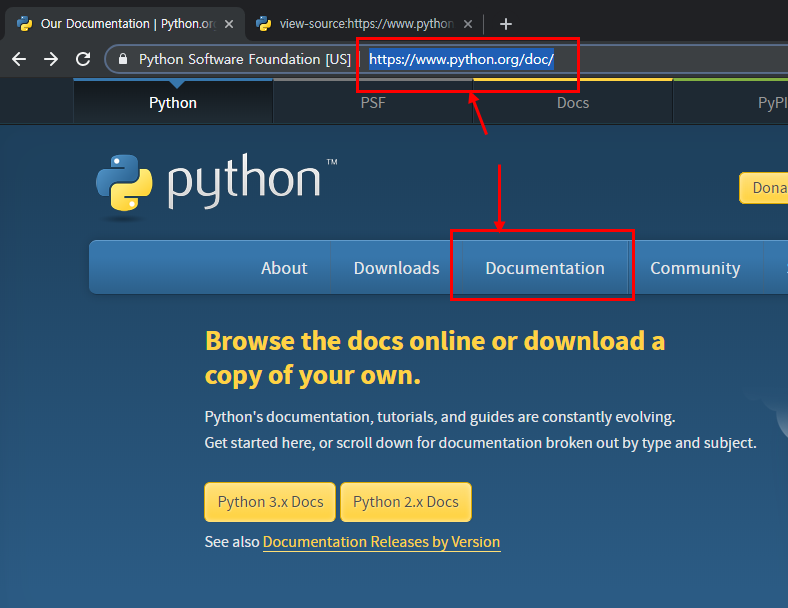
이제 크롤링을 하기 전에 여러분이 크롤링 하고 싶은 사이트를 선택하셔야 합니다.
저는 파이썬 공식 홈페이지에서 Documentation (www.pyhton.org/doc) 를
크롤링 해 보겠습니다.
저와 동일한 사이트를 크롤링 해보시려면 www.python.org 에 접속하셔서
Documentation 를 클릭하시면 됩니다.
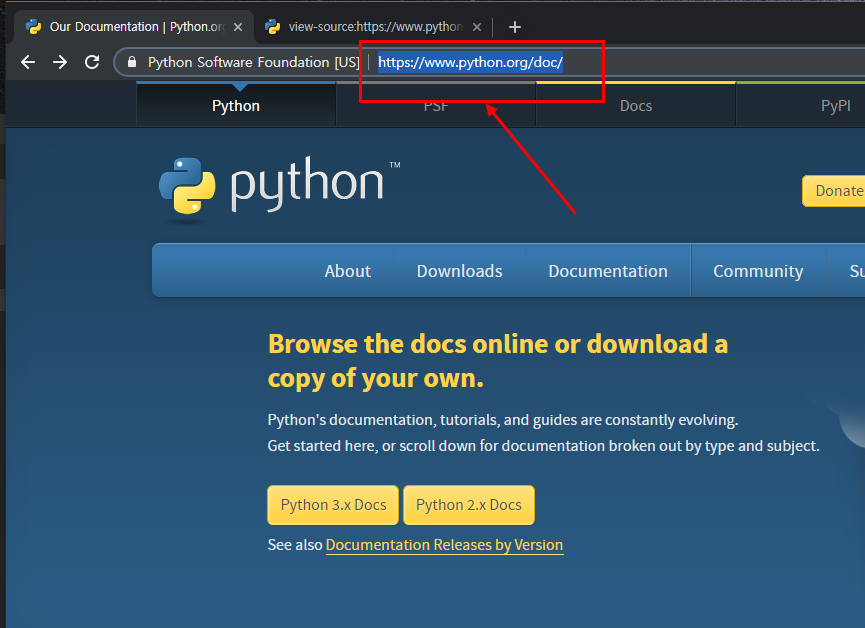
크롤링할 대상을 확인합니다. 저는 www.pyhton.org/doc 입니다.
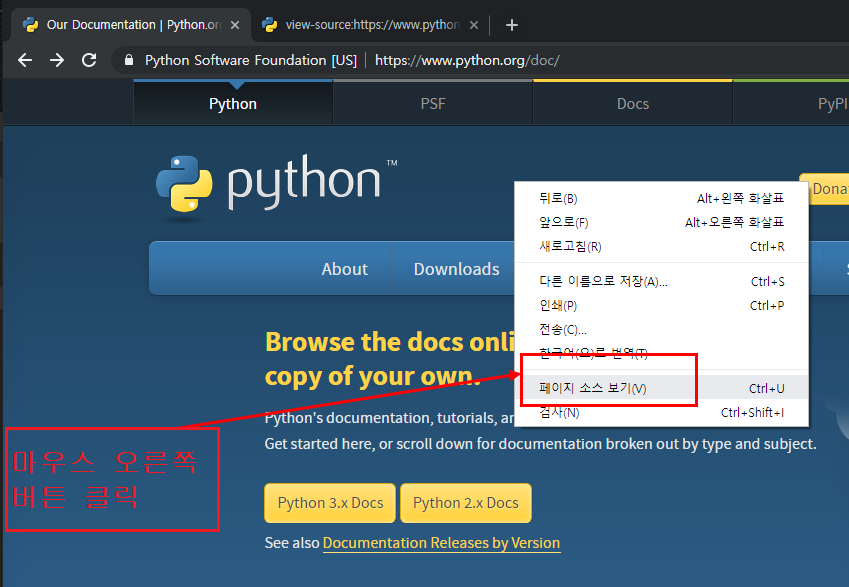
크롤링 할 페이지 화면에서 마우스 오른쪽 버튼을 클릭하시고 페이지 소스 보기를 클릭합니다.
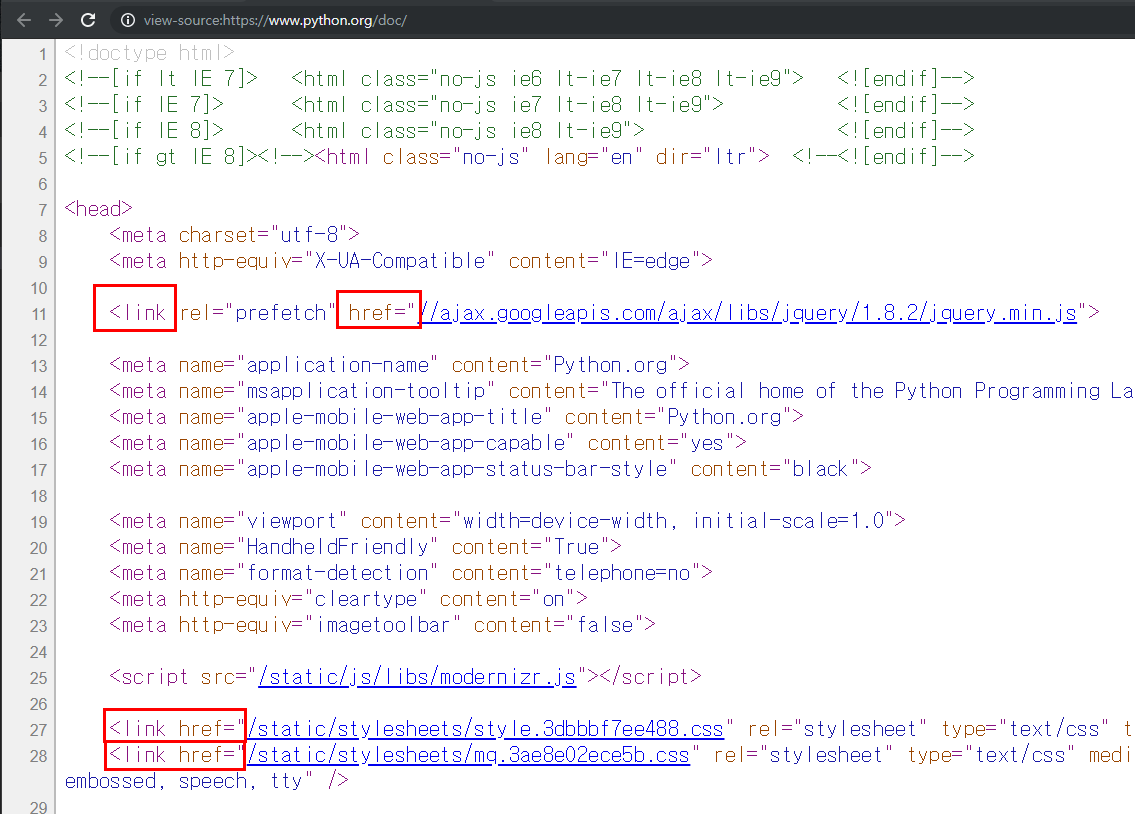
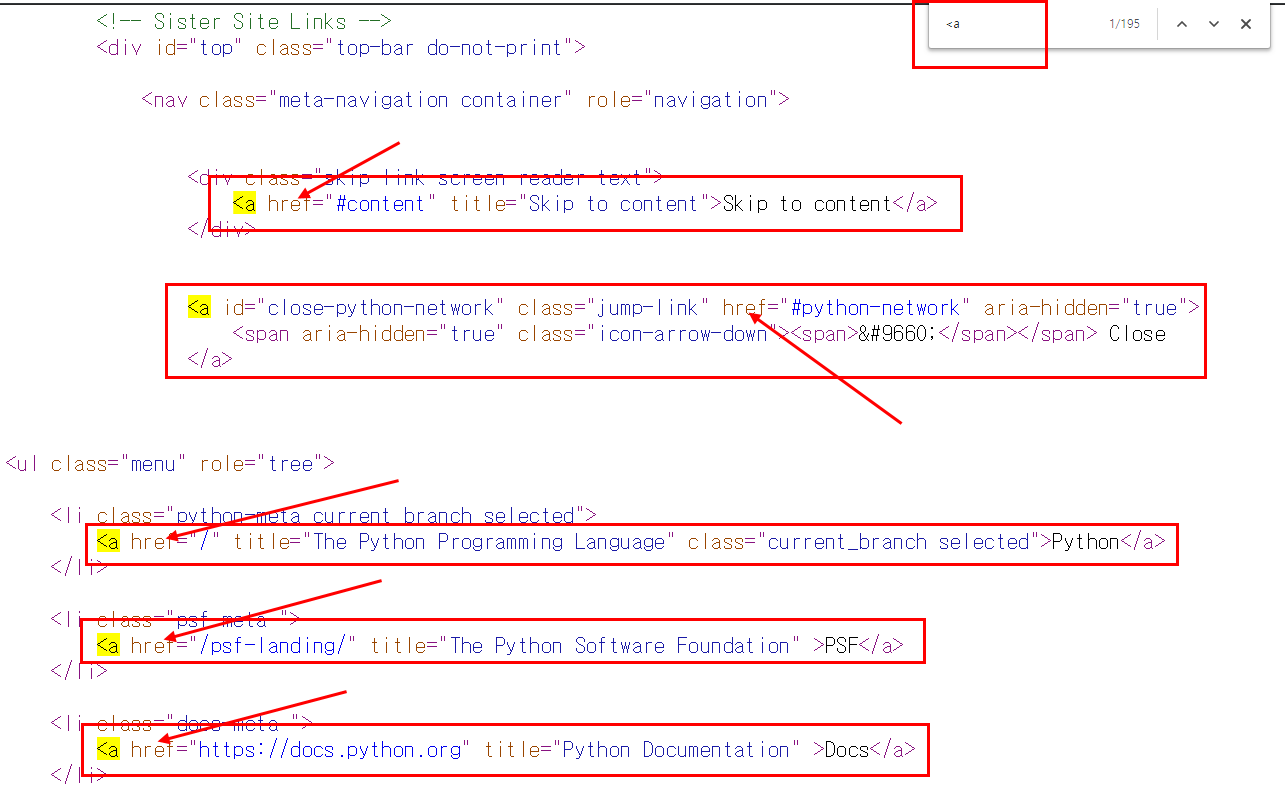
위와 같은 화면이 보이실 겁니다. 저는 <link > 라는 태그를 크롤링 해보겠습니다.
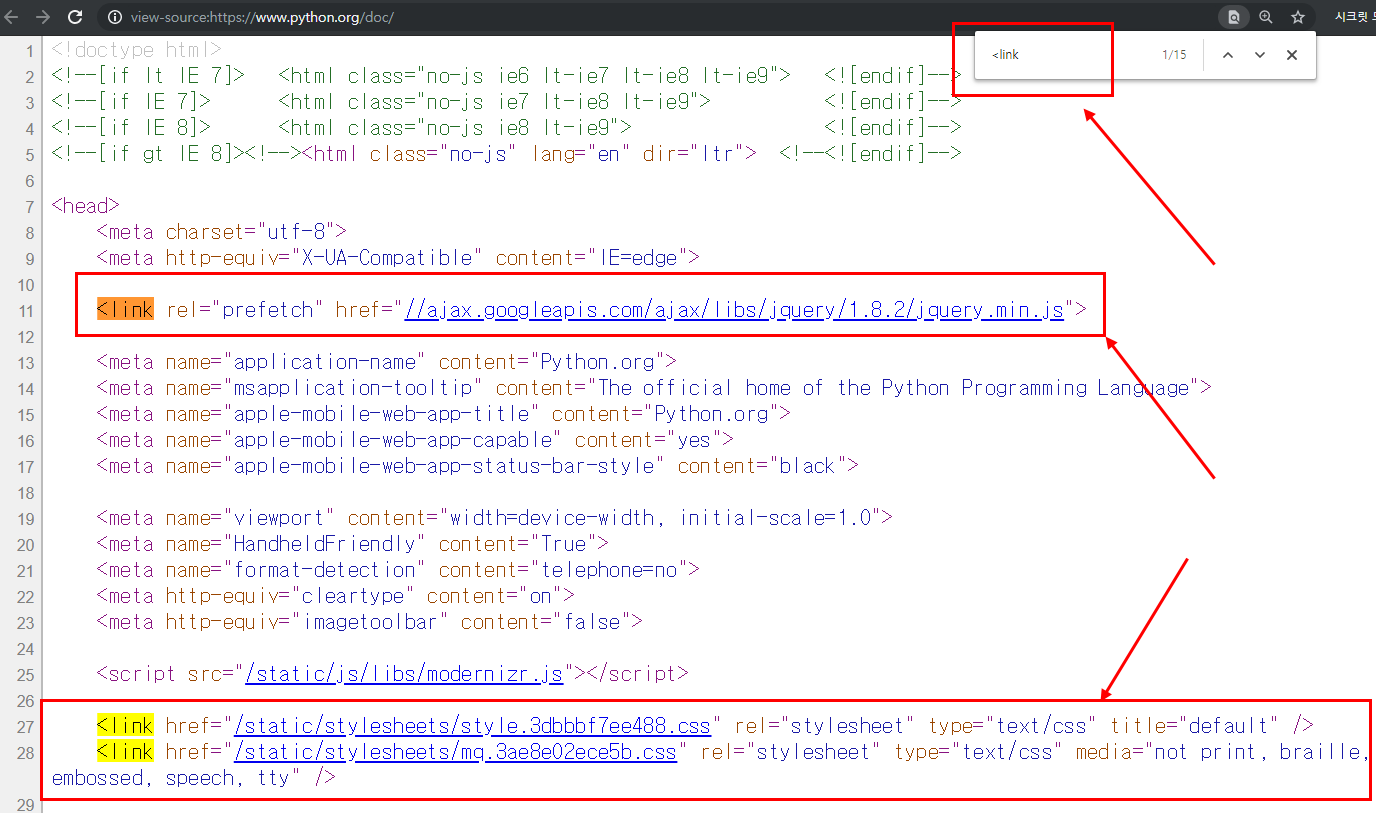
Ctrl + F (찾기 단축키) 를 클릭하셔서 <link 를 검색하시면
크롤링 할 대상들을 확인하실 수 있습니다.
<link > 라는 태그를 찾아서 저는 href 라는 단어가 있으면
그 해당되는 내용을 불러오게 해보겠습니다.
위와 같은 경우는
//ajax ... ,
/static ...
...
같은 내용들이 불러와지겠죠?
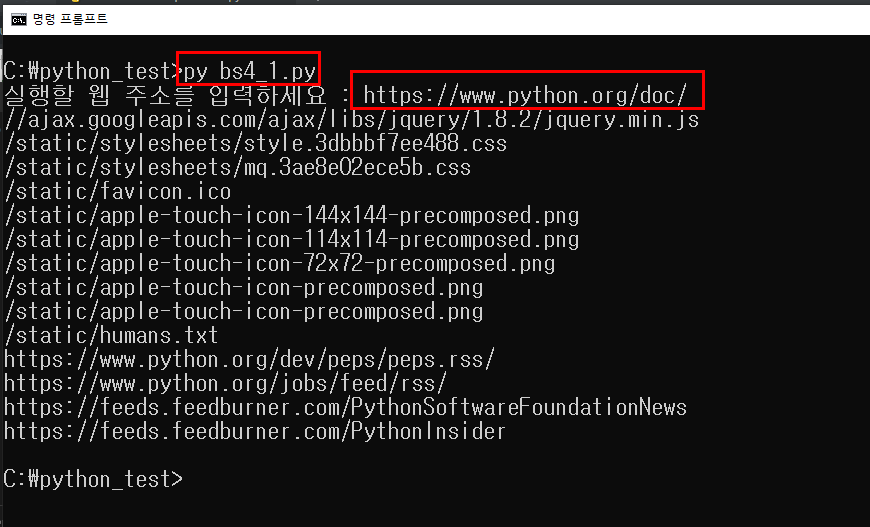
이제 정상적으로 불러오는지 아까 개발한 파일을 실행해 보겠습니다.
py bs4_1.py 로 실행을 하시고
( bs4_1.py 부분에 여러분이 개발해서 저장한 파일명을 입력하세요.)
실행할 웹 주소를 입력하세요 : 라는 문구가 나오면 거기에 사이트를 입력하시면 됩니다.
파일을 수행했을 때 바로 밑에 결과를 확인해보면
저희가 예상한 데이터가 잘 출력되는 것을 확인하실 수 있습니다.
이번에는 <link > 태그 대신에 <a > 태그를 크롤링하도록 변경하고 저장해보겠습니다.
저희가 크롤링 할 대상들을 미리 확인해보겠습니다.
#content
#python-network
...
위와 같은 내용들이 불러와지면 정상이겠죠?
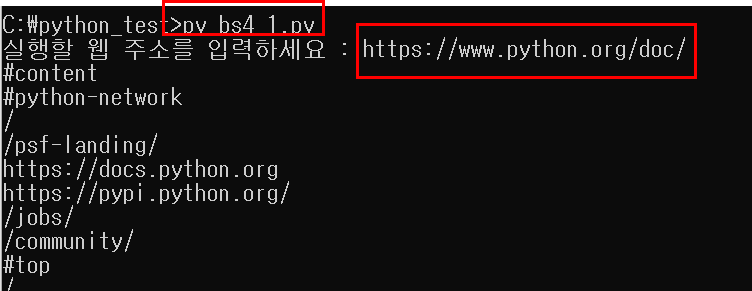
해당 파일을 실행하니 위와 같이 예상된 값들을 잘 불러오는 것을 확인할 수 있었습니다.
이상으로 beautifulSoup 을 활용한 파이썬 웹 크롤링 예제를 알아보았습니다.
고맙습니다.
'파이썬 python > 웹 크롤링' 카테고리의 다른 글
| No Module Named bs4 beautifulsoup python 파이썬 (0) | 2019.05.10 |
|---|---|
| 파이썬 크롤링 크롤러 설치 python BeautifulSoup bs4 (7) | 2019.05.09 |